Software Complexity as Entropy
A perspective through information theory, complexity theory, and mathematical logic

Introduction
Software complexity is often described in shallow terms: bad code, poor planning, or weak engineering discipline. But this misses a deeper truth.
Every software system encodes an irreducible amount of information about the problem it is solving. This is not an accident of bad design — it is entropy.
In this essay, I argue that software complexity is entropy: the irreducible information content inherent in a problem domain. It cannot be eliminated. It can only be transformed, re-encoded, or approximated.
This framing situates software squarely within the lineage of information theory (Shannon, 1948), algorithmic complexity (Kolmogorov, 1965), computational complexity (Cook, 1971), and mathematical logic (Gödel, 1931; Turing, 1936).
Entropy in Information Theory
Claude Shannon defined entropy as:
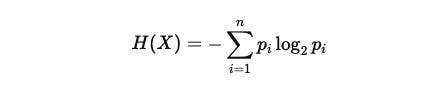
where X is a random variable with outcomes {x₁ … xn}. This quantity represents the minimum number of bits required to encode or predict the system【Shannon 1948】.
Key properties:
Entropy sets a lower bound on representation.
Lossless compression cannot reduce entropy; it only reorganises information into shorter codes matched to probabilities.
Lossy compression reduces entropy only by destroying fidelity — discarding states, shrinking the problem space.
Applied to software: you cannot represent a problem domain with fewer bits than its entropy without sacrificing correctness.
Kolmogorov Complexity: The Irreducibility of Description
Kolmogorov complexity defines the complexity of a string as the length of the shortest program that generates it【Kolmogorov 1965】.
Regular strings (e.g., 010101...) are compressible.
Random strings are incompressible — their Kolmogorov complexity is essentially equal to their length.
Implication for software: Every problem has an irreducible description length.
Abstractions, frameworks, and notations may re-encode the description, but the entropy is conserved.
Any “simplification” that claims to reduce complexity below this bound is either hiding it (lossless encoding) or discarding parts of the problem space (lossy).
Computational Complexity and Lower Bounds
Entropy expresses itself in algorithmic limits:
Sorting lower bound: Any comparison-based sorting requires Ω(n log n) operations. Why? Because there are n! possible orderings:
bits are required to distinguish them【Knuth 1998】.
NP-completeness: Many problems (e.g., SAT, scheduling) have no known polynomial-time solutions because their entropy is too large to be compressed below exponential size【Cook 1971】.
Distributed consensus and FLP impossibility: Fischer, Lynch, & Paterson (1985) proved that in an asynchronous distributed system, deterministic consensus cannot be guaranteed if even a single process may fail【Fischer et al. 1985】. The irreducible entropy here is timing uncertainty: a system cannot distinguish between a failed process and a slow one.
In each case, entropy imposes fundamental lower bounds.
Software as Axiomatic Systems
Software is not “just code.” It is a formal system, like mathematics.
A Turing machine is the canonical model of computation: a finite set of states, an alphabet, and a transition function. It is not a computer but a mathematical description of computation itself【Turing 1936】.
Writing software is equivalent to defining axioms, states, data types, concurrency rules, architectural assumptions, and contracts/interfaces.
Executions outcomes are derivations: logical consequences of those axioms applied to inputs.
Entropy enters because the problem domain’s information load must be faithfully mapped into this axiomatic structure. If axioms align with the domain, complexity is coherent. If not, entropy manifests as hidden fragility.
Thus, software is mathematics which operates with axioms. The work of engineering is the work of axiom selection and entropy governance.
Compression, Fidelity, and Fragility
Compression illustrates why complexity cannot be reduced:
Lossless compression: Re-encodes entropy into shorter representations but preserves all states. Execution always requires re-expansion. Complexity returns in full.
Lossy compression: Truly reduces entropy, but only by discarding states. This reduces coverage of the problem domain, leading to failure cases when those discarded states appear in reality.
Therefore, complexity can only be:
Encoded differently (lossless, entropy preserved). OR
Reduced at the cost of correctness (lossy, entropy destroyed).
Incompleteness and the Limits of Formal Systems
Kurt Gödel (1931) proved that any sufficiently powerful formal system (capable of arithmetic) is incomplete:
There exist true statements that cannot be proven within the system.
The system cannot prove its own consistency.
Alan Turing (1936) translated this into computation via the Halting Problem: there is no general algorithm that can decide for every program and input whether the program will halt.
Implication for software:
You cannot prove all properties of a sufficiently complex system.
There will always be behaviours that are undecidable from within the system.
This incompleteness is another form of irreducible entropy: the uncertainty we cannot eliminate.
The Role of Engineering: Entropy Management
Given these constraints, engineering is not the elimination of complexity but its management and the accompanying axioms:
Assumption governance: Make axioms explicit, test their alignment with reality.
Decomposition: Partition entropy into smaller subsystems with bounded scope.
Risk-first execution: Address high-entropy uncertainties early.
Entropy isolation: Use interfaces to prevent local entropy from contaminating global stability.
Accept approximation consciously: When lossy methods are used (e.g., heuristics), know what part of the problem space is being discarded.
Conclusion
Software complexity is entropy: the irreducible information inherent in a problem domain.
Shannon entropy shows the lower bounds of information content.
Kolmogorov complexity shows the irreducible description length.
Computational limits (sorting, NP-completeness, FLP) show the hard constraints entropy imposes on algorithms.
Gödel and Turing show the incompleteness of formal systems, ensuring unpredictability.
Software is mathematics: an axiomatic system encoding entropy. Its complexity cannot be reduced — only transformed, managed, or approximated.
The task of software engineering is not to eliminate entropy but to govern it and understand the axioms involved, with humility toward the limits that theory has already proven unbreakable.